

Artificial intelligence (AI) and deep learning using neural networks is a powerful technique for enabling advanced driver-assistance systems (ADAS) and greater autonomy in vehicles. As AI research moves rapidly, designers are facing tough competition to provide efficient, flexible, and scalable silicon and software to handle deep learning automotive applications like inferencing in embedded vision. Although these techniques may be freely applicable to non-safety-critical aspects of a vehicle, such as infotainment systems, the rigors of meeting the functional safety requirements for the safety-critical levels of ISO 26262 should give designers pause. Selecting proven IP, developing a safety culture, creating rigorous processes and polices, and employing safety managers are required for designers to meet their ISO safety requirements and achieve ASIL readiness for systems using neural networks. Extensive simulation, validation, and testing, with a structured verification plan, will also be a requirement for meeting the standards’ requirements in vision-enabled ICs.
AI Applications in Vision-Enabled ADAS Systems
AI and deep learning are improving ADAS systems and enabling autonomous vehicles because they are significantly improving the accuracy in object and pedestrian detection and recognition of multiple objects, which traditional algorithms have had trouble performing. AI enables cars to perform even semantic analysis of the surroundings, which is essential when your car needs to assess the environment and events in the vicinity.


The two major areas where AI appears in automotive applications are infotainment with a human machine interface (HMI), and ADAS or autonomous vehicles. An HMI includes speech recognition (natural language interface), gesture recognition, and virtual assistance, which are already deployed in today’s vehicles. These systems are starting to take advantage of the deep learning advances, and no longer just rely on generic AI. The second area, ADAS/autonomous vehicles, is much more complex. These systems use cameras, long-range and short-range radar systems, and LIDAR for object recognition, context evaluation, and even action prediction.

Impact of AI on Software Development
From a software point of view, deep learning creates a significant paradigm shift in terms of the programming and implementation of algorithms. With traditional computer vision, a designer would write a program to figure out if, for example, a particular shape is that of a person in a pedestrian detection application. The program analyzes each image of a video input frame by frame to determine if the image includes a person. The histogram-oriented gradients (HOG) algorithm, an object detection technique developed before deep learning, analyzes edge directions of shapes in an image to detect specific objects (Figure 1).

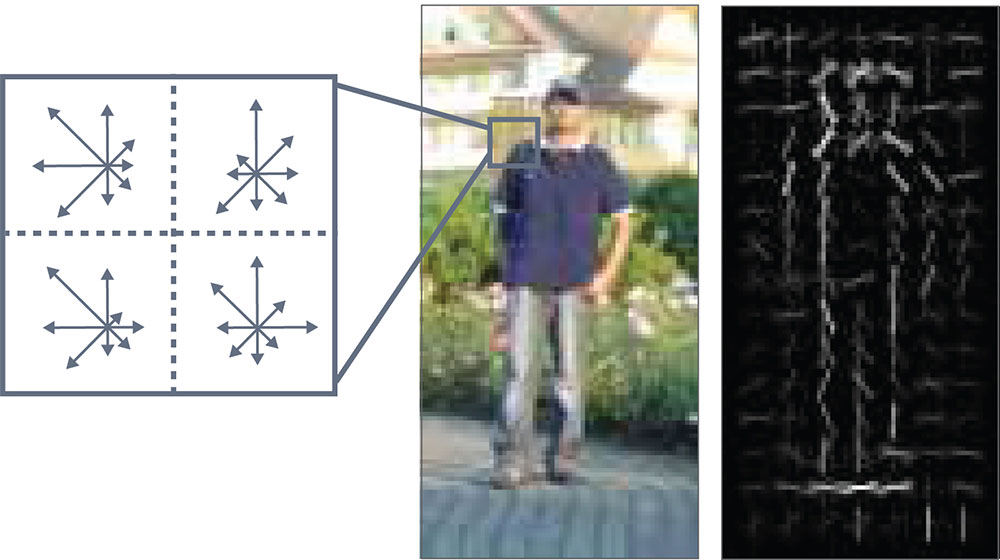
Using traditional computer vision algorithms like HOG can take years of engineering effort to hand craft the algorithms to identify a full set of objects as you add cars, different types of trucks, dogs, bicycles, and so on. A neural network, on the other hand, takes the raw input data and uses it to “learn” how to make decisions about what to find in the image. A neural network has an input layer and an output layer, and a deep neural network, which includes three or more layers, has multiple hidden layers in-between the input and output layers (Figure 2). Each of the layers include individual nodes that can learn, and each node is weighted based on the multiply-accumulates feeding into the nodes. This process is part of the training of the neural network and is not directly programmed.

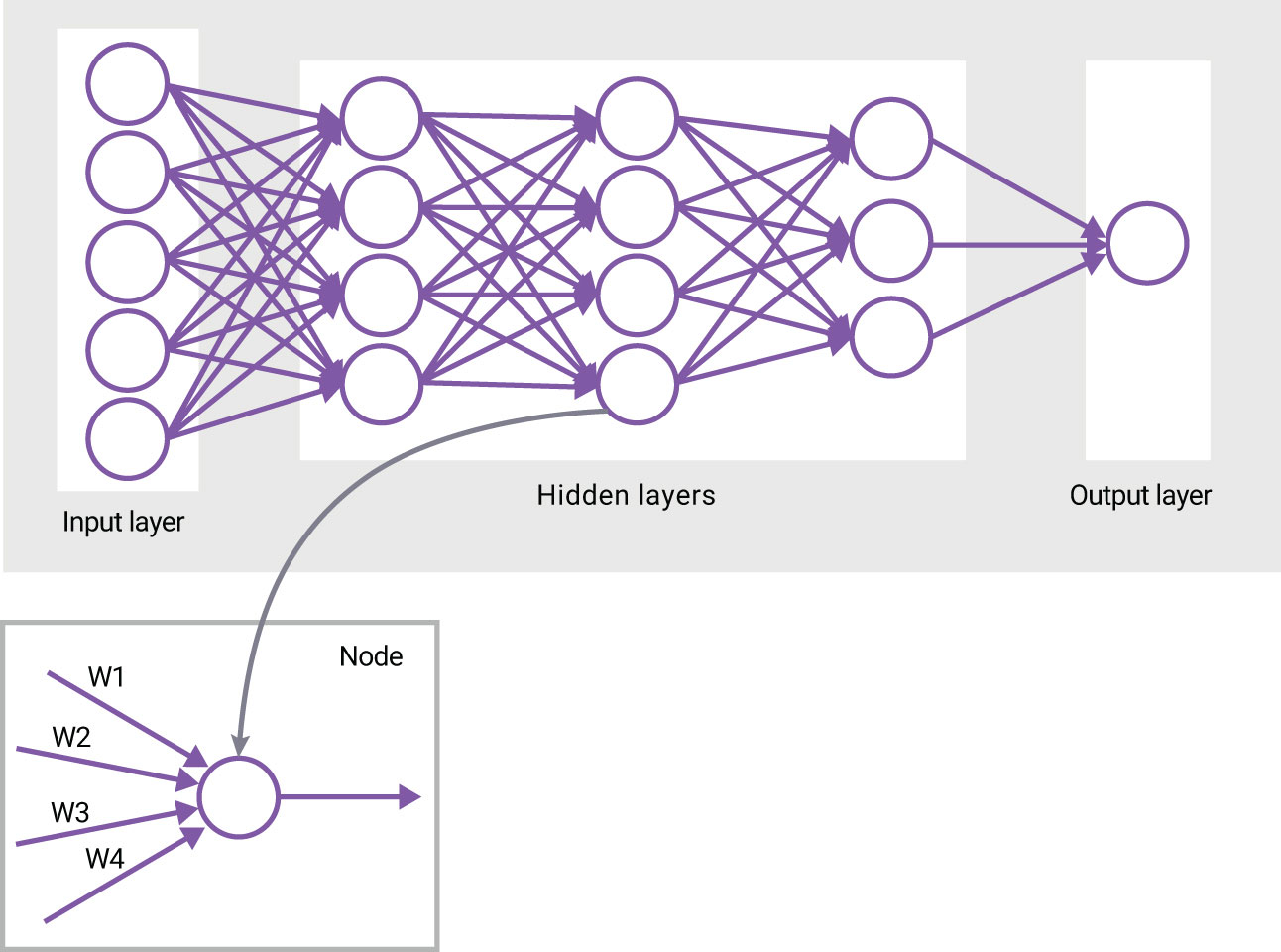
In a neural network, every node is connected to every other node. Its multiple layers replace the traditional computer vision algorithms for many applications such as detecting objects, classifying the objects, facial recognition, gesture recognition, etc. It does not completely replace the need for a programmable solution, as pre-processing and post-processing are required. However, because of their significant improvements in accuracy, DNNs have become the de facto standard for classification, detection, recognition, and similar analysis.
Convolutional Neural Networks for Automatic Emergency Braking
Convolutional neural networks (CNNs) are a specific type of DNNs that have become the state-of-the-art technique for image recognition. A CNN processes each image of a video input frame by frame. Using a CNN, each image is convolved with a filter to produce intermediate feature maps. This is repeated over multiple layers to extract low-level features, mid-level features, and high-level features for applications such as pedestrian detection in automatic emergency braking (AEB) systems (Figure 3).

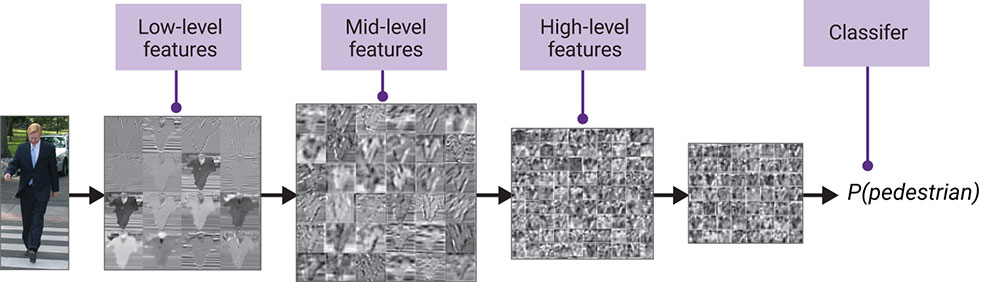
The low-level features might be curves or edges. Mid-level features might be circles (a combination of curves), or boxes or squares (a combination of edges), and so on, until shapes such as arms, legs, and torsos are identified (assuming the network was trained to recognize pedestrians). The last layer is fully connected to put all of the analysis back together. In essence, the computer or machine takes an image, breaks it down into small pieces, then builds it again to make a decision: is that a pedestrian, based on all these curves and edges and lines, or is it not a pedestrian? This decision is made based on the CNN’s training phase.
Training and Deploying CNNs
The programming experience for AI applications has changed from traditional computer programming, as there are now two phases (Figure 4). The first phase, training, is where the network is trained to recognize items. The second phase, inference or deployment, includes the hardware that runs in the embedded environment, i.e., in the car. The training phase is usually done in a cloud data center, with one or more GPUs, while the inference phase occurs in the end product.

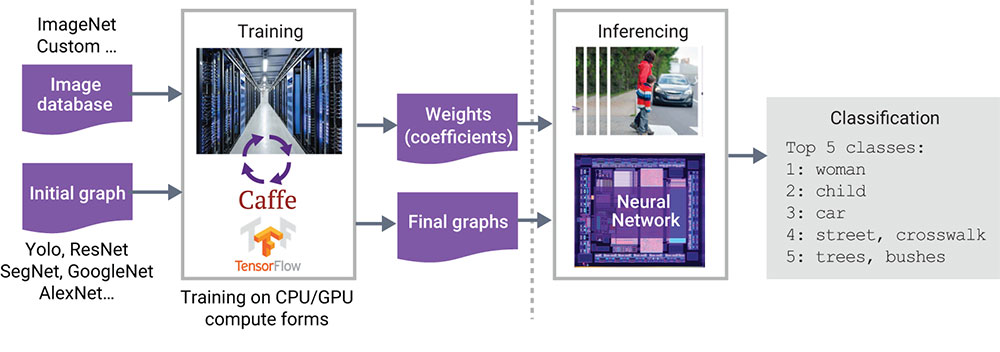
The network is trained by feeding it annotated images in the training phase. The network ‘learns’ to recognize the desired objects by adjusting the coefficients, or weights, of the network through many iterations. If the network is trained well, the weights and network can be transferred to the embedded system where objects can be recognized in the inference phase within a car. The output of a neural network in the inference phase is essentially a probability of what the neural network was trained for. If it is trained to look for a pedestrian, the neural network will return a probability that the input image included a pedestrian. The next step is to take it to a higher level and determine how to have the car make a decision about what to do with the image, like a stop sign. AI and deep learning apply in this stage as well, because the system can be trained on what to do in different situations.
AI & Hardware Development
The output of the training process is a 32-bit floating point number. For an automotive inferencing implementation, designers are looking for the smallest, most accurate piece of hardware possible because both functional safety and power are challenges. Understanding bit resolutions compared with area and power enables designers to create the smallest possible piece of hardware. In the last few years, the hardware has been developed to combine with these new neural network algorithms to create small, fast, low-power SoCs with embedded CNN capabilities.
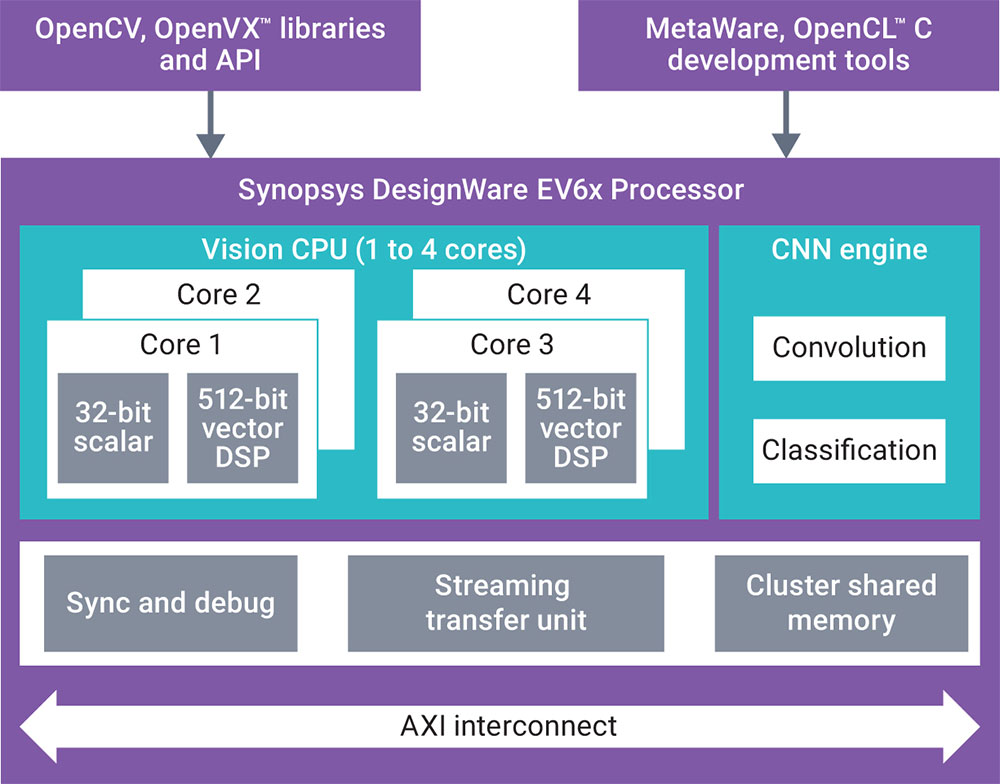
Embedded vision processors, like the DesignWare EV6x Embedded Vision processors with tightly integrated CNN (Figure 5), enables designers to scale their designs while meeting their performance, power, and area requirements. Scalar and vector units perform the pre-and post-processing, while the CNN engine manages the deep learning tasks. Of course, software is critical to program these efficiently.

Neural Networks are a Moving Target for Hardware Developers
One of the challenges of hardware design that uses AI technology is, of course, that this is all a moving target. The neural networks are constantly changing. Classification networks have evolved from AlexNet to GoogLeNet to ResNet and beyond. Object recognition, the combination of classification and localization to identify not only what the object is, but also where it is, adds another layer of complexity and further computational requirements. This is also a rapidly evolving class of neural networks with Regional CNN (RCNN) giving way to Fast RCNN giving way to Faster RCNN and now SSD and YOLO variants.
To add to the computational challenges, the cameras and resolutions within cars are changing. Today’s car has 1 or 2 megapixel cameras, OEMs are rolling out 3 or 4 megapixel cameras, and 8 megapixel cameras are in the pipeline. That much resolution gives you more visibility but also drives designers to integrate more processing horsepower. Upgrading frame rates from today’s 15-30 fps to the coming 60 fps will enable shorter stopping distances as long as latency remains low.
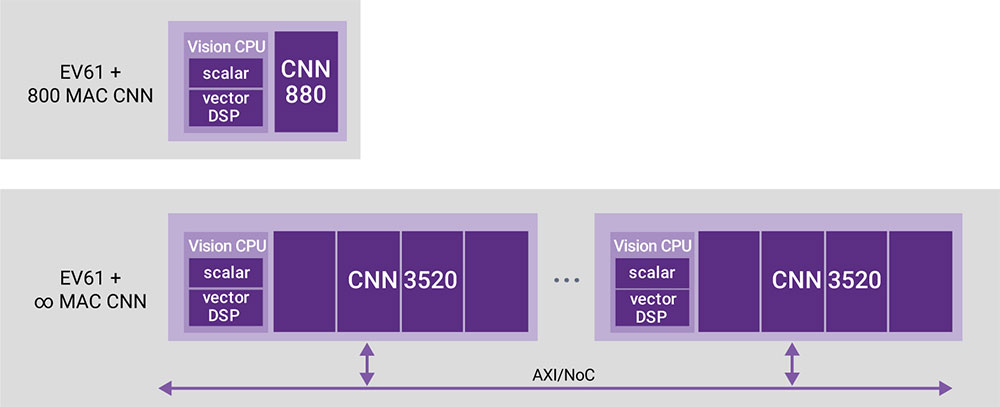
This increase in resolution and frame rates means that a neural network that offered 64 multiply-accumulates was enough a few years ago, but soon after the requirement changed to 800-100 MACs. Today, designers are planning for 50 TeraMACs/s of performance with a low power budget to handle multiple cameras.
To help designers address these rapidly changing requirements, Synopsys offers the DesignWare EV6x Embedded Vision processors, which include a dedicated neural network engine and vision cores, as well as the MetaWare EV toolkit. This combination of traditional computing, neural network engines, and software, enables designers to create both small-area SoCs for driver-drowsiness detection as well as fast, safety-critical SoCs for autonomous driving. The DesignWare solution was developed to scale for a wide range of applications, but uses the same basic hardware and software building blocks.

Meeting Functional Safety Standards
AI and neural networks are improving ADAS applications and enabling self-driving vehicles – however the public will not accept these autonomous vehicles without a strong confidence in the safety of the systems. The automotive industry requires that vehicle systems function correctly to avoid hazardous situations, and can be shown to be able to detect and manage faults. These requirements are governed by the ISO 26262 functional safety standard, and the Automotive Safety Integrity Levels (ASIL) it defines.

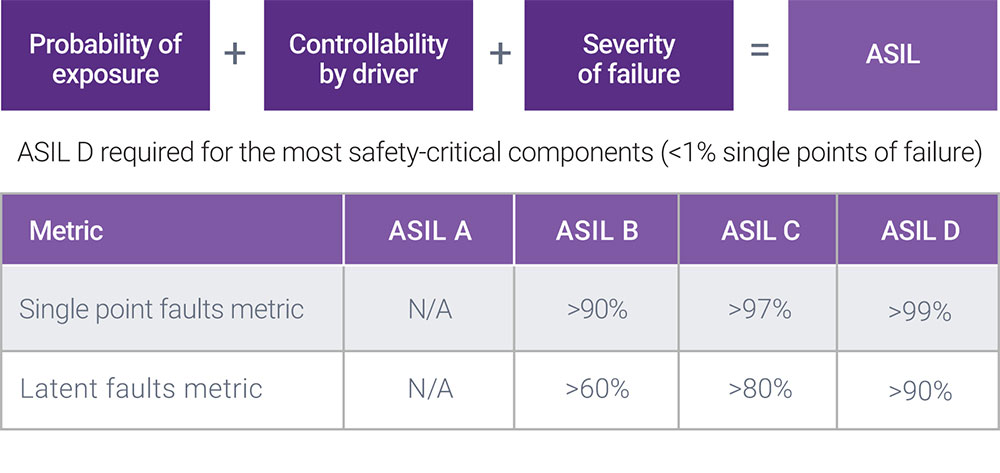
The place for deep-learning systems within the requirements of ISO 26262 is still being defined. It may be that for infotainment systems, it will be quite straightforward to achieve ASIL Level B. But as we move towards the more safety-critical applications requiring ASIL C and D, designers will need to add redundancy to their systems. They’ll also need to develop policies, processes, and documentation strategies that meet the rigorous certification requirements of ISO 26262.
In this case, running at 50 TeraMAC/s is the first challenge, but designers need to add redundancy and fault tolerance to meet ASIL requirements. Synopsys is investing into solutions to help designers achieve ASIL B for systems like infotainment, and ASIL D for safety-critical applications. Developing an SoC that meets ASIL B requirements for one SoC might not be acceptable for the second iteration of the SoC because the next design may need to meet ASIL D requirements for a more autonomous vehicle.
In addition to its broad portfolio of ASIL B and ASIL D Ready IP, Synopsys has extensive experience of meeting the requirements of ISO 26262 and can share our experience on developing a safety culture, building a verification plan, and undertaking failure-mode effect and diagnostic analysis assessments. Synopsys also has a collaboration with SGS-TUV, which can speed up SoC safety assessment and certifications.
Summary
Automotive system designers are already using traditional embedded-vision algorithms. One of the key enablers of vehicle autonomy will be the application of AI techniques, particularly those based upon deep-learning algorithms implemented on multi-layer CNNs like embedded vision. These algorithms show great promise in the kind of object recognition, segmentation and classification tasks necessary for vehicle autonomy.
The integration of AI into automotive systems is changing how software and hardware engineers design systems, as they meet the high bars of performance, power, area, and functional safety. Engaging with an IP vendor that has a successful track record of delivering ASIL-ready IP, like Synopsys, will help system architects achieve market success for their products.